This article was originally published in Dutch in the VX Company Magazine, issue #2 in May 2022.
In this article we’ll look at the relationship between TDD and software design in three different ways. We’ll look at the two styles of TDD (the Classicist style and the Outside-In style) and how they deal with software design. Next we’ll look at some software design decisions and how they impact the practice of TDD. Finally we see if there’s a ‘sweet spot’: a certain software design and approach of writing tests that offers the most benefits.
Part 1: the two styles of TDD
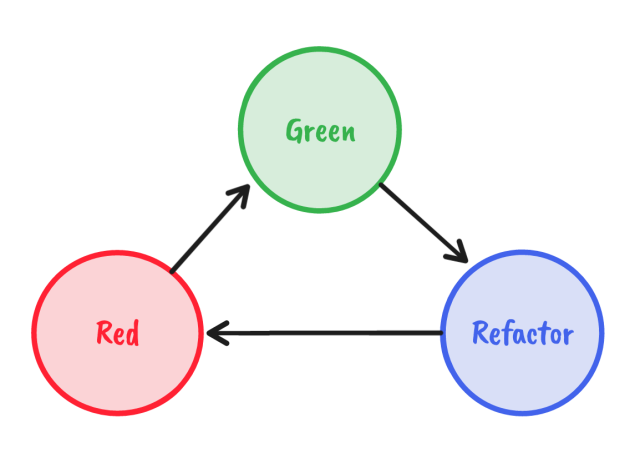
Broadly speaking, there are two major styles of Test-Driven Development. These style are usually called the Classicist style (or Detroit style) and the Outside-In style (or London style). Both of them follow the same basic workflow, consisting of 3 steps: first write a test, which will of course fail because you haven’t written any production code yet. Next, write just enough code to make this test pass. Finally, remove any duplication and apply other refactor techniques to clean up your code. Repeat these steps until your feature is done. These steps are often the red, green and refactor steps of TDD.
Let’s look at a simple example: a very basic web shop. Imagine you have a Register class and you would like to add a feature where a 10% discount is applied on every purchase. You would start in the red phase with a test (the examples are in C#, but the principle applies regardless of your programming language):
[Fact]
public void A_fixed_10_percent_discount_is_applied_at_checkout()
{
var subtotal = 100;
var total = _register.ApplyDiscount(subtotal);
Assert.Equal(90, total);
}
This test will fail. Actually, this code won’t even compile, because you haven’t written the ApplyDiscount method yet. So the first step towards green would be to add that method:
public int ApplyDiscount(int n)
{
throw new NotImplementedException();
}
The code now compiles, but the test still fails because of that Exception. The fastest way to make the test pass would be this:
public int ApplyDiscount(int n)
{
return 90;
}
Green! But not quite the end result that we’re looking for yet, because obviously this doesn’t complete the feature. We need an extra test to force us to write the correct implementation.
This step might seem ridiculously small. However, especially when learning TDD, this is an important intermediate step. It teaches you not to make any hasty assumptions, and to really drive the design of your algorithm from the tests.
If you use a test runner that supports parameterized tests, now’s a good time to use it. In xUnit, you can use a Theory:
[Theory]
[InlineData(100, 90)]
[InlineData(200, 180)]
public void A_fixed_10_percent_discount_is_applied_at_checkout(int subtotal, int expectedTotal)
{
var total = _register.ApplyDiscount(subtotal);
Assert.Equal(expectedTotal, total);
}
The first scenario still passes, but now the second one fails. This test forces us to evolve the implementation of our code:
public decimal ApplyDiscount(int n)
{
return n * 0.9m;
}
This brings us back to green. And that now takes us to the refactor phase. Do we have any duplication to eliminate, or other ways to improve the code? In this simple examples there’s duplication, but the naming of certain variables isn’t quite clear. We can improve the way this code communicates its intent by using more descriptive names:
private const decimal DiscountFactor = 0.9m;
public decimal ApplyDiscount(int subtotal)
{
return subtotal * DiscountFactor;
}
Again, this is only a trivial example, but it does clearly demonstrate the red/green/refactor loop of TDD.
Classicist TDD
This red/green/refactor flow is a staple of both Classicist and Outside-In TDD. The above example however is a clear example of Classicist TDD. In this style, all of the important design work occurs in the refactor phase. The red and green phases make it work, it’s only in the refactor phase that you clean up the code and improve on the design.
The reason for this approach is the following: your brain isn’t very capable of doing 2 things simultaneously and doing them both well. It’s hard to both solve the problem and create beautiful, well-designed code at the same time. That’s why these activities are split into separates phases. In the red and green phases, your goal is to get from red to green as fast as possible. Anything goes! You are allowed to break any rule, copy and paste your own code, copy and paste code from StackOverflow: whatever you need to do to get to green quickly.
First make it work, then make it pretty
In our example, this clearly showed in the first step: the first implementation returned the hard-coded value “90”: the simplest solution to get the test to pass. In the next iteration, we had a working solution, but it wasn’t very clean yet. Then, during the refactoring phase, you take the time to clean up your solution. You might want to extract code into separate methods, or introduce new classes. You might notice that certain design patterns could be used to clean up the code: now’s the time to apply them. In this simple example, the refactoring was limited to introducing and renaming a couple of explanatory variables. All the while, you use the tests you’ve just written to verify that your refactoring doesn’t break anything.
Classicist TDD and Emergent Design
The Classicist style of TDD shows the principle of Emergent Design. This means that you listen to the feedback of the tests and the code that you’re writing to guide your design decisions. But what does this mean: listening to the feedback of your tests? In this case we’re not talking about the test result (green/red, pass/fail), but about the experience of writing the test and the production code. Was it hard to come up with a proper name for your test? Did your test code require a lot of tedious boilerplate setup code? Does your test depend on data that must be in exactly the right configuration for the test to be valid? Is there a lot of duplication in your production code, is there confusion about certain concepts, or are there a lot of hidden assumptions? All of this is feedback that you can use to improve the design of your code. In this way, the final design of your software emerges based on the experiences you have when writing the tests, i.e. Emergent Design.
In our simple web shop checkout example, we wrote the test and then came up with the simplest solution we could think of:
return 90;
Only after adding a test did we have a need to expand on this logic:
return n * 0.9m;
And after one more iteration, we improved on the intent of the code:
return subtotal * DiscountFactor;
This is a micro example on a very small level, but the same principle applies for larger changes: you let the final design emerge based on the addition of extra test cases. Once you spot duplication or other code issues, you refactor.
Does this mean you can throw away all of your design knowledge, and simply listen to the feedback of your tests? Hardly. Tests might provide feedback that some piece of code is not quite well written, but you still need to apply your skill and experience to recognize this in the first place. Sometimes, duplication can be quite subtle. Or perhaps some other design rules (e.g. the SOLID principles) or guidelines are violated. And after recognizing the problem, you still need the skill to come up with a proper solution.
So, what’s the benefit of Emergent Design then, if at the end of the day you need to apply all of your design skills anyway? I think there’s a couple:
First, the process of TDD and emergent design really pinpoints which parts of your code need cleaning up. In the Classicist style, you are allowed (encouraged!) to write as quick and dirty code as you can to get from red to green as quickly as possible. This by itself is a great way to find out which points of your code need cleaning up: you don’t have to think about which design might be good and which might not be, you can see the ugly bits right in front of you, so all you need to do is clean it up.
Second, the process creates trust. By building up your design step-by-step, using tests all the way through, you can be confident that all of your code is covered by tests.
Finally, Emergent Design protects against over-engineering. If you don’t practice TDD and you try to come up with a complete design up front, you might be tempted to introduce architectures and design patterns way too early. While such constructs can be very powerful, if you apply them incorrectly they only add unnecessary complexity. By practicing Emergent Design, you have a built-in safeguard against over-engineering: you will only apply such patterns once you actually see the problem in your code. Only then will you apply a fitting pattern to solve this.
Outside-In TDD
And then there’s the second major style of TDD: Outside-In TDD. When you practice this style, you build up your system from the ‘outside’ edges inward, starting at for example an API controller in a web service, or the command prompt in a CLI application. Being TDD, of course you start in red with a failing unit test. But now, in contrast with Classicist TDD, the design work already starts here.
Imagine writing a test for an API Controller. Even while writing the test, you consider that you don’t want to write any business logic in the Controller, and you want the Controller to delegate the work to some Service class. That is what you will be testing for. So you’re not writing a (too) simple naive implementation, as you would with the Classicist style, but you start thinking about the design of your system right away, while still in the red phase.
Sticking with our web shop example: imagine there’s an API controller with a Checkout endpoint. This endpoint should again apply the 10% discount. With Outside-In TDD, you already decide during the red phase that you don’t want to calculate the discount in the Controller, but you want to delegate this to a separate service.
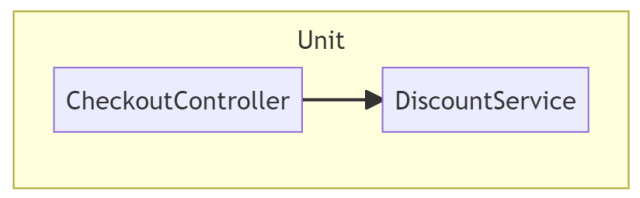
When you write the test, you’re no longer interested in the result of the Controller action, you’re interested in the behavior of the Controller: does it call the Service? Does is pass the correct parameters? In other words, you’re not testing state, you’re testing behavior.
To test whether the Controller calls the Service correctly, you often use Mocks instead of the real service in this style. The mock service looks just like a real service (it implements the same interface), but it contains no behavior. The only added feature of the mock is that it can verify whether it has been called correctly.
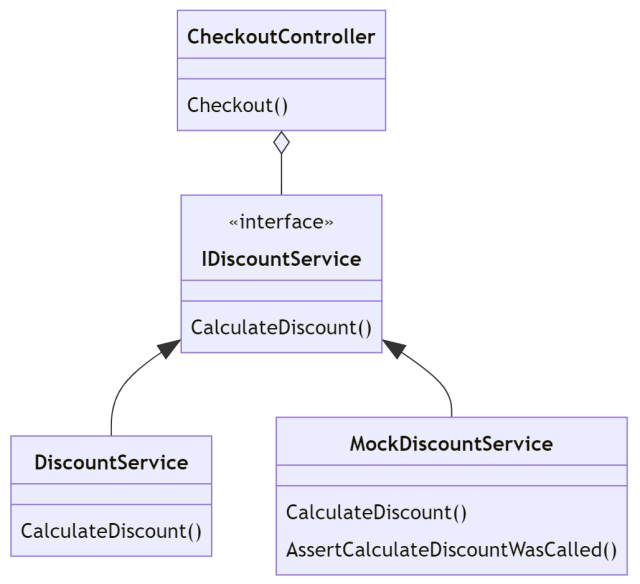
The test will look something like this:
[Fact]
public void Controller_calculates_a_discount_on_checkout()
{
var service = new MockDiscountService();
var controller = new CheckoutController(service);
var subtotal = 100;
controller.Checkout(subtotal);
service.AssertThatCalculateDiscountWasInvokedForSubtotal(subtotal);
}
As you can see, the test no longer asserts that a certain result has the expected value. Instead, it asks the MockDiscountService whether it was called with the expected arguments. Often, you would use a mocking framework to verify this (such as Moq or NSubstitute when writing .NET code), but it’s quite easy to implement such a mock yourself. In our example, the mock service looks something like this:
public class MockDiscountService : IDiscountService
{
private const int Dummy = 0;
private int? _subtotal;
public int CalculateDiscount(int subtotal)
{
_subtotal = subtotal;
return Dummy;
}
public void AssertThatCalculateDiscountWasInvokedForSubtotal(int subtotal)
{
if (!_subtotal.HasValue || _subtotal.Value != subtotal)
throw new Exception($"Expected CalculateDiscount to have been called with {subtotal}");
}
}
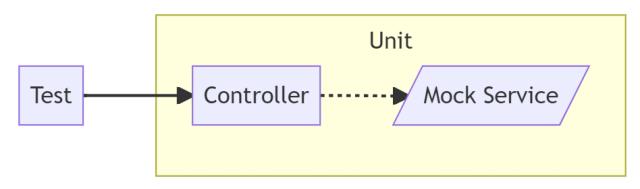
When you get to the green phase, you build up the implementation of the Controller. Finally, the refactor phase is typically quite short: you might want to change the name of a variable or method, or extract a helper method somewhere. But since you’ve already made the major design decisions in the red phase, there’s usually no big refactoring step required.
When you’ve implemented the Controller, you go to the next layer of your application. In this case, the DiscountService, and starting implementing it in the same way: write out a test and think of the behavior that you want out of the service. Implement it, clean it up, and then work your way to the next layer, until the entire feature is implemented. This way, you work your way from the outside of your system to the inside, hence the name: Outside-In TDD.
Most developers tend to prefer one style of TDD over the other. Even so, the styles are not mutually exclusive and it can be helpful to master and understand both styles. For an extensive comparison between of these two styles, see the article Mocks Aren’t Stubs by Martin Fowler. And if you prefer to read a good book, look up Test-Driven Development By Example by Kent Beck (on Classicist TDD) and Growing Object-Oriented Software Guided By Tests by Steve Freeman and Nat Price (on Outside-In TDD).
Part 2: the influence of design on TDD
In the previous chapters we’ve explored how the different schools of TDD handle software design. But the relationship between TDD and software design goes both ways: your software design also impacts the way you can practice TDD.
Let’s start with an obvious example of this situation: legacy code that has not been written with testability in mind. If you have to work in such a codebase, this strongly determines the way you can apply TDD practices. ‘Doing’ TDD will almost always be possible mind you, but such a codebase might present some challenges. You will probably need to do some refactoring to make the code better testable. You’ll have to create seams to separate code into modules. And once you’ve done that, you can begin to change and evolve the modules using a test-driven approach. In such a codebase, you are often pushed towards micro-test: unit tests that test only a small, shallow part of the code, where all dependencies of that part of the code are replaced by test doubles. Writing test for larger ‘units’, such as a collection of related classes, is almost impossible due the way the code is structured.
Tip: in this screencast, Sandro Mancuso demonstrates a number of techniques that you can use to bring legacy code under test.
Design choices determine the ease with which you can write tests
Some architectures are intrinsically better suited to TDD than others. I’d like to mention two of them. The first would be architectures that are built using functional programming for the majority of the code. In such a code base, you tend to compose your system from pure functions as much as possible (i.e. functions that always produce the same output given the same input, and that do not have any side effects). By their nature, such functions are usually quite easy to test. If most of your system is composed of easily testable functions, you won’t have much trouble writing unit tests and finding a nice TDD flow.
Then there’s the domain-centric architectures. You might know these as Clean Architecture, Onion Architecture or Ports-and-Adapters (Hexagonal) Architecture. These types of architectures are also quite well suited to TDD. A distinguishing feature of such architectures is that they separate the core of the application, which models the domain the the behavior of the application, from the ‘infrastructure’ parts of the application, which handle the interaction with the outside world, such as the UI, the database, and the network. By separating these concerns, writing tests for your domain logic will be quite easy, because the ‘hard stuff’ (such as the database) has been abstracted away. And writing tests for the interaction with the outside world can focus solely on that part: the interaction between the outside world and your application, and it doesn’t have to deal with your application logic as well.
How strong is the coupling between your tests and your production code?
There’s another design concern: how strong is the coupling between your tests and your production code? One of the promises of TDD is that you build up a safety net, such that you can safely refactor your code to keep it clean, maintainable and easy to extend. If you make a mistake during refactoring, your tests will catch it. But refactoring can be big or small. Changing the name of a variable or method is a relatively small change, but changing the structure of classes or introducing certain design patterns can be quite a big change. And there’s the rub: the stronger the coupling between your tests and your production code, the harder it will be to perform larger refactoring techniques. And the other way around: the looser the coupling, the more freedom you have to apply even a quite large refactoring.
This point shows a clear difference between the two TDD styles. When doing Classicist TDD, there is usually quite little coupling between the tests and the production code. This gives you a lot of freedom to refactor. The tests only exercise the external visible API of your code, and have no knowledge at all of the internal implementation. By contrast, Outside-In TDD often uses mocks to drive the tests, which assumes a lot of knowledge about the internal implementation of the production code, causing a much tighter coupling.
Does this mean that Classicist TDD is by definition ‘better’ than Outside-In TDD? Not necessarily. When doing TDD, you need to have a lot of flexibility to perform refactoring. This styles prescribes that you go from red to green as quickly as possible, and only refactor and improve the design when the test passes. When doing Outside-In TDD, most of the design work is done during the red phase. That is the time to think about the structure and design of your code. During the refactor phase, all that’s left is relatively minor ‘clean up’ work, because all major decisions have already been made. So there’s much less need to have a lot of freedom to refactor.
Part 3: the sweet spot
In an ideal world, you would only have very fast, easy to write end-to-end tests: these types of tests provide the ultimate confirmation what your entire system works as intended. You’re only using production code, no mocks or stubs, and nothing is tested in isolation. This means you’re testing both the individual parts, as well as their interaction with each other. These kinds of tests do not make any assumptions about the design of your system. They only test the externally visible inputs and outputs. This gives you the ultimate freedom to refactor.
In practice, this is actually quite impractical to achieve. These types of tests tend to be complex to write. They are usually highly dependent on data being in the exact right state. Testing all combinations of input and output at this level can be a lot harder than testing certain parts in isolation. And they are quite slow to execute, making them very inconvenient for a typical TDD cycle.
The opposite isn’t ideal either: having only a suite of micro-tests that test all parts of your system in isolation. These tests are quite easy to write, since they only touch a very small part of your code base. And since you isolate any external dependencies such as the database and the network, they execute very fast. The risk of these types of tests is that you introduce a tight coupling between your tests and your production code. If you replace all collaborators of a class with test doubles, you embed a lot of knowledge about the implementation of the production code into your tests. This greatly reduces your ability to refactor the code. Besides: these kinds of tests don’t test the integration of your system: you’ll need to build additional tests to very that all individual parts work well together.
In my experience, for the types of applications that I typically encounter, there does seem to be some kind of sweet spot: a combination of design and an approach to doing TDD that provides enough design guidance, without introducing a lot of complexity for your test setup. This setup leaves a lot of room to refactor, while still keeping the test suite fast.
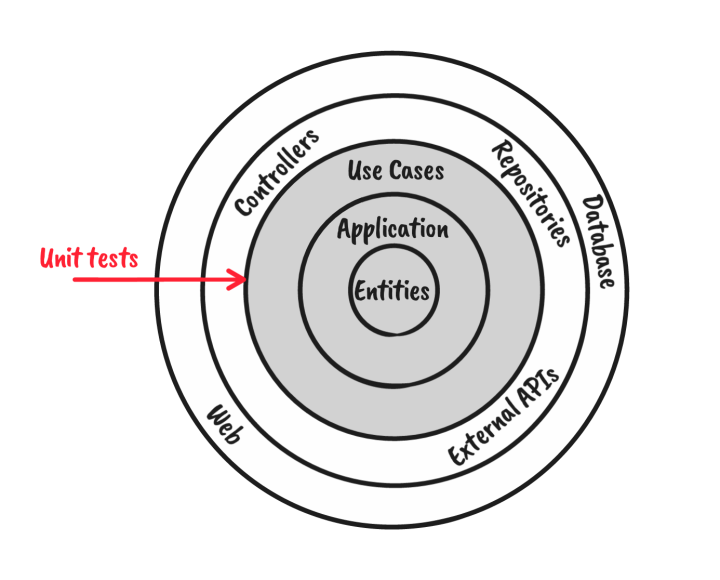
This sweet spot uses a combination of domain-centric architecture, and a test suite that executes at the boundary of your domain model. In terms of Clean Architecture, this would be writing tests against your Use Cases. Or in terms of Ports and Adapters: writing tests against the Ports. Tests are mainly built using a Classicist style, and do not require any knowledge about the internal implementation of your module (any domain services and/or entities that make up the core of you application). This gives you a lot of freedom to refactor your code. The use of test doubles is minimal, and mostly limited to replacing external systems such as a database with a simple mock or stub. If you combine such test with a few integration or end-to-end tests, you can build up a pretty decent test suite: you can do TDD in a very powerful way, where your tests are only very loosely coupled to your production code and can remain fast and light weight, while still allowing you to easily get your entire system under test, resulting in maximum confidence in your code.
In conclusion
The basics of Test-Driven Development are simple. The core dynamics of red/green/refactor are easily explained using a simple example. Yet applying this in a larger system quickly adds a lot of complexity. So much so in fact, that various styles of TDD have emerged that both approach the workflow of TDD and designing your software in a very different way. The best thing you can do is to familiarize yourself with both of these styles, and practice their methods using simple exercises. Find basic katas such as the FizzBuzz kata or the Roman Numerals kata to practice Classicist TDD. Try the Bank Account kata to get a feel of Outside-In TDD. And learn about domain-centric architectures to see how this can help you apply TDD in real-life projects. And before you know it, the red/green/refactor mantra is ingrained in your head and your fingers!
Comments